Database Change Management: Tarantino review
Last week, Chris Alcock included a mention of an article .NET Database Migration Tool Roundup in The Morning Brew #109. Both Bruce and I read this and came to the same conclusion, that Tarantino might be worth a look to stop us from continuing writing our own tool to manage the change process reliably. Today we invested some more of our ILP time into examining how it works, and what it does.
Firstly, there isn't much documentation, so we had to fumble around a bit to work out how to use it. I read the wiki page with interest, and found myself agreeing with what was said there. I especially liked the quote:"Successful database change management requires that a consistent process be applied by all team members. Without a consistent process than the tools provided in this solution will not provide its full value"
We found that this documentation, and the process description validated our aims and thoughts on how the process should work, suggesting:
- a local database for each developer - this works for me on 2 levels, firstly in the same way that a good developer wouldn't check their code into source control until it was complete, the database changes shouldn't affect anyone else until this stage either, and secondly database changes get tested by other team members
- changes are implemented as SQL scripts
- there is a predefined order in which the SQL scripts should run
We aren't, initially, looking at a tool that needs to integrate with an automated build environment, so we didn't need a lot of the features that Tarantino offers. Instead we concentrated on the Tarantino.DatabaseManager.exe application and worked with that. The result of this is that some of our requirements aren't met by the DatabaseManager but may be met by some of the other aspects of Tarantino.
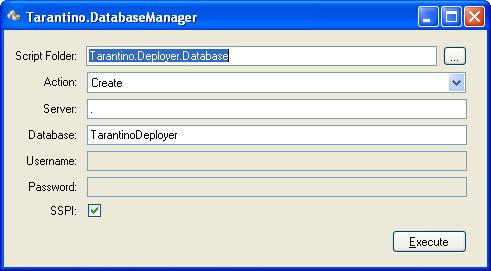
- Create - the default. This will create the database identified in the Database field (I didn't find how you specified the settings for database creation during my 1.5 hour investigation, but I'm sure it's there somewhere). It will then update the database identified in the Database field according to scripts found in the Update sub-folder of the folder specified in the Script Folder field, running them in alphabetical order.
- Update - This will update the database identified in the Database field according to scripts found in the Update sub-folder of the folder specified in the Script Folder field, running them in alphabetical order if they haven't already been reported as run in the table of scripts
- Drop - This will drop the database identified in the Database field
- Rebuild - This will combine the Drop and Create tasks above.
DatabaseManager uses file naming as a convention for determining the order in which the update files will run - the recommendation for naming is 0001_Script.sql, 0002_Script.sql etc however during our investigation we discovered that we could leave Copy of 0001_Script.sql hanging around and this would just get appended to the list in alphabetical order. We were somewhat concerned that during the development process amongst a team, more than one person could be working on database updates at a time (and when using a local database, there is no guarantee that anyone else would know about it) which could mean, at best, two files with the same prefix, i.e. 0003_AddTableArticles.sql and 0003_FixBug12122.sql and at worse a source control conflict of 0003_Script.sql. This is where naming conventions would obviously come into play. During our discussions we liked the idea of some form of dependency mapping - i.e. 0003_AddTableArticles.sql is dependent on the change 0001_Script.sql. This would obviously help us to ensure that errors with code vs database versioning could be avoided. This isn't provided within Tarantino.
"Create a change script that wraps all of the database changes into a single transactional change script. A Tool like Red Gate SQL Compare makes this a 30 second operation."
This unfortunately means that error handling is poor and transaction handling is non existant. One of our tests was to create a file containing invalid SQL amongst the (valid and not applied) change scripts. The error was reported in the output window amongst nAnt exception reporting - making it quite hard to track down. When the error occurred, then data relating to the preceding SQL files in that Update batch will remain in the database but the subsequent files will not even be called - this leaves the database in a state of uncertainty. The table usd_AppliedDatabaseScript gets a row added for any previous files successfully completed, but the Version gets left as NULL. When I corrected the SQL and re-ran the process, the Version column gets updated to match the version number for the rest of the files successfully applied in the batch. This results in different date/time stamps on the rows, but the Version number being the same which makes me wonder if tracking the version history of the database is then subject to a certain amount of interpretation. In addition, selecting the action Create from the user interface when the database already exists results in an exception being raised - in my opinion this should be handled via some defensive SQL coding.
Note: All tests were carried out on a Windows XP laptop running a local installation of SQL Server 2005.We have previously, also looked at DBVerse to meet our requirements. As neither tool satisfies what we're attempting to do, we'll continue writing our own but this was a worthwhile diversion as it really validates our thoughts on process vs program, and how that process should look.